
Backgrounder
China’s Generative AI Ecosystem in 2024
Rising Investment and Expectations
Paul Triolo and Kendra Schaefer examine both the opportunities and challenges facing the AI sector in China. They consider how AI developments in China are driving U.S.-China technology competition and intersect with critical policy choices around technologies that support AI ecosystems.
Outside of large U.S. tech platforms and a handful of major players in Canada and France, the country with the most developers of large language models (LLMs) and applications is clearly China. The generative artificial intelligence (AI) landscape is vibrant, and includes a mix of large tech platforms, social media companies, and more recently a slew of well-financed start-ups.
In this backgrounder, we examine both the opportunities and challenges facing this sector in China. We also examine how developments in AI in China are driving U.S.-China technology competition and how they intersect with critical policy choices in Washington around technologies that support AI ecosystems. For policymakers broadly, including those considering technology controls and AI governance frameworks, understanding what is really happening in China’s vibrant generative AI space, led by private sector actors and venture capital (VC) funders, is critical. The vast majority of generative AI development and all related innovation in China is led by the private sector, and Chinese companies and researchers remain heavily engaged with global ecosystems and trends. Policymakers around the world seeking to develop AI governance frameworks are increasingly wrestling with the reality that excluding China—and, more importantly, Chinese companies—from discussions of critical issues such as AI safety, frontier model regulation, and alignment would almost certainly be counterproductive to developing a global approach.
China’s Generative AI Ecosystem in 2024
China’s generative AI space is rapidly expanding and evolving, with many established tech platforms iterating models, new start-ups entering the fray, and investors struggling to understand business models, use cases, and revenue generation prospects. Since a previous analysis of this issue in September 2023, a lot has changed.
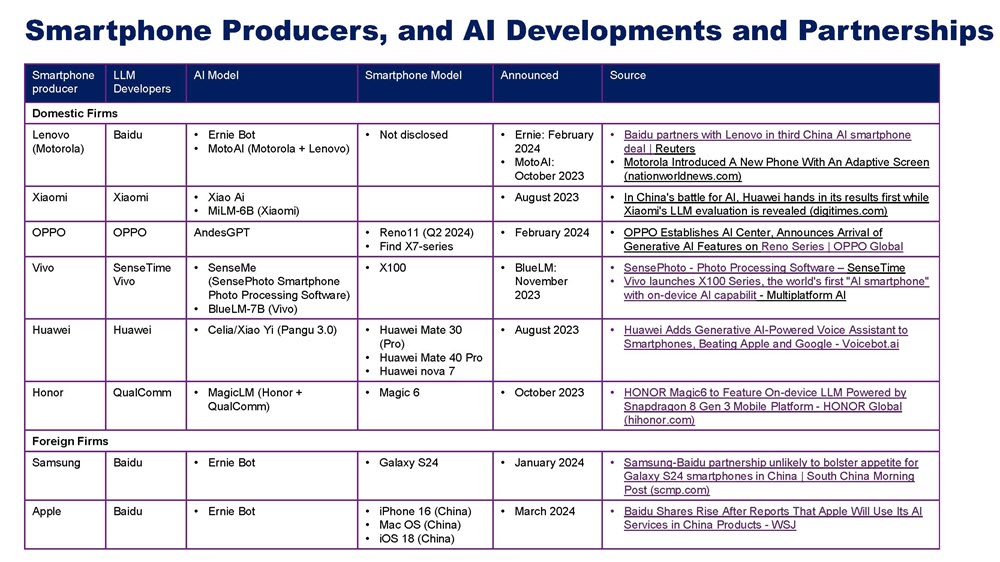
China’s generative AI industry remains in the early stages of development. Established and new AI players are seeking investment, as well as developing, fine-tuning, and iterating LLMs, while end users are experimenting with different approaches to deploying applications on enterprise networks. As in the United States and other developed country markets, companies are eager to begin leveraging the benefits of LLMs in business processes but are reluctant to commit to a particular platform, LLM, or company for support. Not only is it still unclear which market leaders will emerge, but companies are also likely to use more than one LLM provider for different applications. Some of the most dynamic AI companies in China are leveraging Western open-source LLMs such as Meta’s Llama-2 and now Llama-3, while the big tech platforms like Baidu are gaining traction for their proprietary models in hot emerging areas like AI-driven smartphones (see Table 1).
The next six to nine months will be a critical period for Chinese AI firms. Model development will continue to stabilize; company models will score higher on benchmarks and compare more favorably with global leaders like OpenAI, Google, and Anthropic; and investments in the infrastructure cycle will near a point where new inputs will be required to keep pace with Western models. Extensive discussions with AI companies in China suggest that the industry will see an increasing number of enterprise deployments attempting to solve real-world problems and beginning to show productivity gains. Within this period, Chinese AI developers will need to begin to determine how to overcome the restrictions on advanced graphics processing units (GPUs) imposed by the Biden administration and begin to show some substantial revenue streams to justify major investments already made in hardware.
China’s AI development environment is notably diffuse, with approximately 50 Chinese companies currently developing models. This stands in sharp contrast to the United States, where a handful of very large deep-pocketed players—platforms such as Google, Meta, and Amazon Web Services (AWS), plus start-ups OpenAI, Anthropic, and Inflection—dominate the landscape. These players are all well-funded, enjoying massive resources and valuations, and are partnered with hyperscaler cloud providers that provide preferential access to “compute,” which is a shorthand for computing capacity and generally refers to the infrastructure, capabilities, and resources dedicated to computational power and data processing at a company or national level. This includes the development and deployment of high-performance computing systems, data centers, cloud-computing facilities, and networks that support advanced computational tasks essential for scientific research, economic development, security, and innovation. By contrast, China’s many AI players are struggling to find access to investment and compute, and they have relatively low valuations, as some investors remain skeptical about their ability to generate real revenue in the near term. This dispersion has caused some leaders in China’s big tech arena, such as Baidu CEO Robin Li, to question the need for so many models. Li has argued, for example, that China only needs two or three really good models to drive adoption of generative AI at the enterprise level.
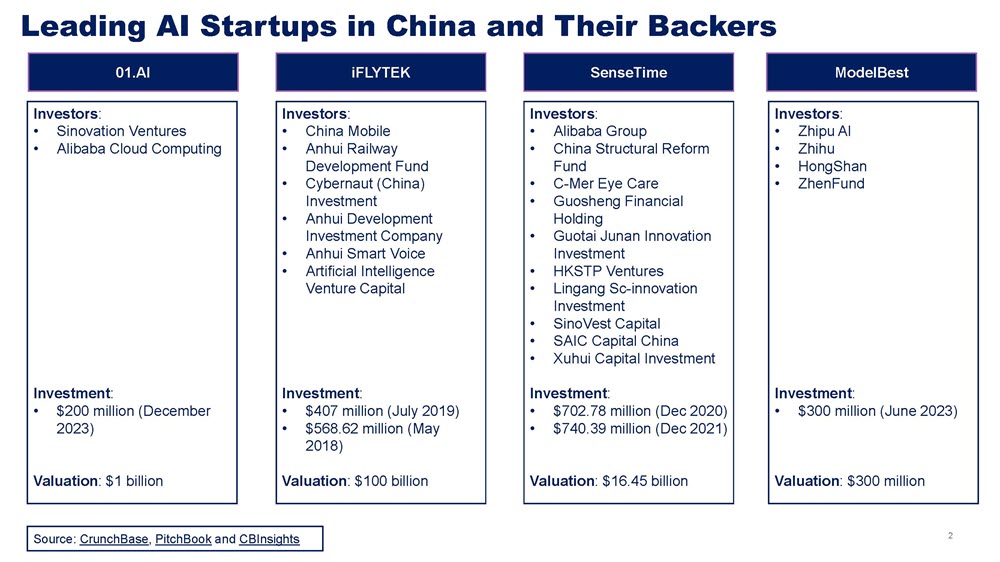
Still, new market entrants funded by both large tech platforms and venture capital firms are emerging frequently and rapidly, indicating that the industry has not taken Li’s advice to heart. A new batch of AI start-ups pursuing LLM development—in most cases backed by large technology company investors and key venture capitalists, boasting $1 billion valuations and packed with engineers and developers with solid industry pedigrees—have also gained traction and investment rounds in the past six to twelve months. Here, a group of start-ups has rapidly risen to the center of the generative AI space in China: Zhipu AI, MiniMax, Baichuan AI, Moonshot AI, 01.AI, StepFun, and Model Best (see Figure 1). A handful of important established domestic VCs remain willing to continue investing in the sector. These include Sinovation, the ZhenFund, Shenzhen Venture Capital, Shunwei Capital, Redpoint China Ventures, Huawei Hubble, Primavera Venture Capital, and others, along with the investment arms of Alibaba and Alibaba Cloud, Tencent, Xiaomi, Ant Group, Meituan, and Kingsoft.
While the revenue potential for such firms is still unproven, enterprise adoption has indeed already begun. Companies such as Baidu are beginning to report earnings that they claim are directly derived from generative AI applications. In late February 2024, for example, Baidu noted in an earnings call that generative AI and foundation models accounted for 656 million renminbi of Baidu AI Cloud’s total 2023 fourth quarter revenue of 8.4 billion renminbi. Baidu noted that cloud services operations had seen over 26,000 ERNIE Bot enterprise users, including Samsung China, Lenovo, and Honor, which will deploy ERNIE on their leading smartphones. In April 2024 Baidu claimed that there were now 200 million users of ERNIE Bot and that 85,000 enterprises had used its cloud platform and created 190,000 AI applications on it. Baidu in April also released three new development tools to facilitate creation of AI agents, applications, and models. Alibaba claimed in May 2024 that its Qwen model was being used at 90,000 enterprises in a range of sectors, including healthcare, mobility, aerospace, mining, gaming, and PCs. The company also claimed that over 2.2 million businesses were using Qwen via its corporate communications app Dingtalk.
While some technical indicators suggest that Baidu’s ERNIE Bot performs better than Qwen, Alibaba has been able to bring to bear its strong cloud-computing infrastructure, longer experience in providing enterprise services, and ability to offer a suite of open-source models to push its Model-as-a-Service (MaaS) platform. Competition for the enterprise market remains heavy, with Baidu competitors Alibaba, Huawei, and Bytedance pushing into this space, offering discounts to attract enterprise users. But as in Western markets, China is not likely to see one or two models emerge as dominant. Enterprises are likely to continue to test multiple models from different companies, unwilling to get locked into one company’s products, and are likely over time to use a mix of models internally, both proprietary and open source, for different types of applications.
As AI companies seek profitability, they face two critical stumbling blocks: the regulatory environment and access to computing power. While China’s cyberspace regulators initially imposed heavy regulation on the sector, the regulatory churn around LLMs has settled down for the moment. The Cyberspace Administration of China (CAC) has issued approvals for the release of more than 40 LLMs over the past six months and granted operational licenses to a total of 1,432 unique, public-facing AI-driven applications. While there is no formal list of all licensed models yet, the CAC has issued some written approvals for public-facing LLMs, including for all the leading platforms and some of the major start-ups, like Kaifu Lee’s 01.AI (see Figure 2). Confusion around the issue of which LLMs are licensed is likely to continue, as the CAC figures out what it wants in terms of a long-term licensing regime, including for foreign-origin LLMs.
Indeed, several signs indicate that China is wrestling with how to balance encouraging AI innovation by allowing developers to leverage foreign models and reducing dependence on foreign LLMs, over which the state has little control. In late May 2024, China’s IT standards body TC260 issued draft security standards for generative AI, which support the implementation of CAC AI regulations released last year. Significantly, the new draft dropped language requiring that providers of AI tools should only use third-party foundation models that have been registered with local authorities, meaning the CAC algorithm registration systems. If the language had been left in, this could have served as a de facto ban on foreign-origin LLMs, as they are not likely to seek registration with the CAC. While regulators remain concerned about the security of foreign-origin LLMs and the dependence of some Chinese AI firms on foreign models, this omission suggests that at least for now, regulators appear more concerned about the negative impact on innovation of banning foreign-origin LLMs than about the security of these models. However, this leeway is likely to be short-lived, and foreign LLMs face an extremely uncertain future in China.
In addition to clearing regulatory hurdles, over the next six months, Chinese generative AI companies will need to determine how to maintain access to a reliable source of advanced GPUs for training frontier AI models. U.S. officials tightened rules around the export of advanced GPUs in October 2023, and Commerce Secretary Gina Raimondo in December for the first time explicitly stated that the purpose of the controls included slowing down Chinese companies in training frontier AI models. The attempts of U.S. GPU leader Nvidia, along with other players such as Intel and AMD, to design compliant GPUs for the Chinese market have run into multiple challenges, and the performance downgrades of Nvidia’s new H20, L20, and L2 GPUs are significant enough that domestic tech giant Huawei’s Ascend 9XX series of data center chips, which include a GPU, are now outperforming the Nvidia offerings on some benchmarks, making major Chinese players less interested in purchasing Nvidia’s China-specific products. Domestic demand for Huawei’s chips is reportedly huge (over a million units), but the firm faces challenges ramping up production at SMIC, which is still working to improve yields on its 7-nanometer (nm) production process.
Benchmarking China’s Generative AI Models
Chinese companies developing LLMs are ramping up efforts to compare their models with leading Western firms using a range of benchmarks designed to measure accuracy of the models against standardized metrics. The most important benchmarking tests remain focused on how well models perform such tasks as language rendering, coding, and math. More recently, “context window size”—or the amount of user input that the model uses to understand the context of the current prompt—has also become an important indicative metric. There is considerable debate in China’s AI community about the use of benchmarking. For example, while there is some prestige in benchmarking against GPT-4, this may not be so useful for assessing a model’s utility for real-world applications. Additionally, there are ways to game benchmarking systems, and it can be difficult to tell which model is good at a particular task by looking at benchmarking results.
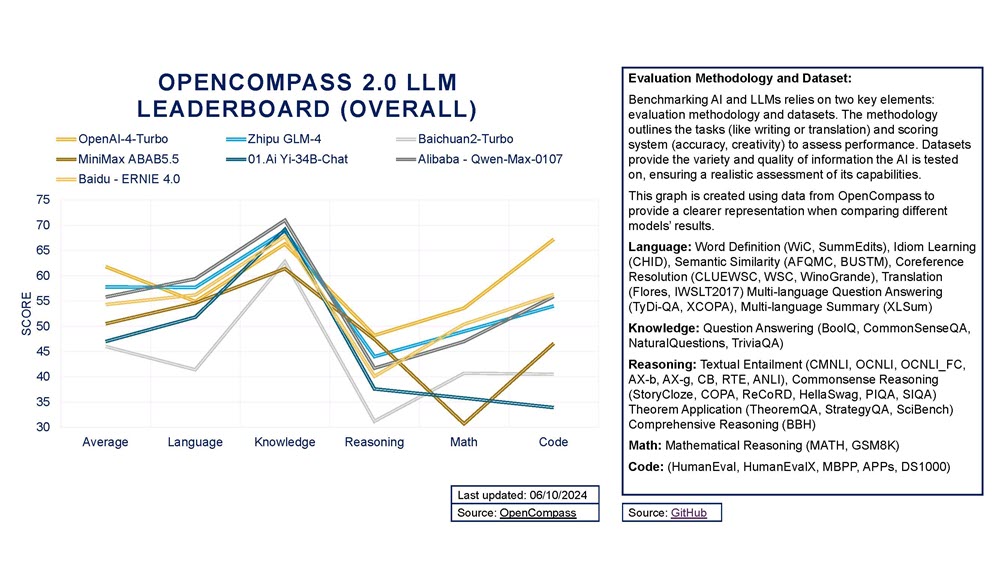
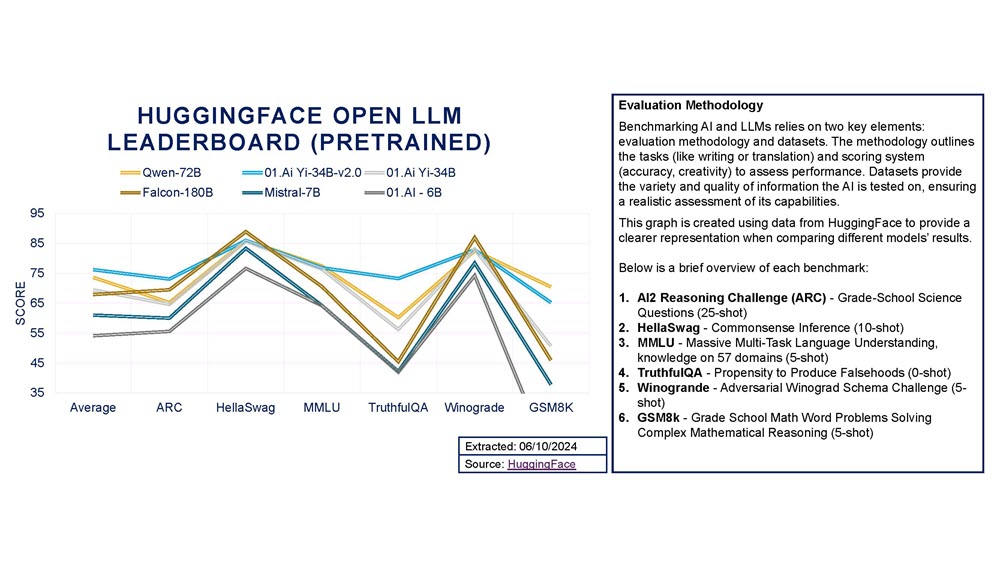
There are a multitude of AI benchmarking and ranking tools, including OpenCompass2.0 run by Shanghai Al Lab (see Figure 3) and Hugging Face (see Figure 4). However, assessing models based on these benchmarks is an art, not a science, and depends on many controversial factors, making it difficult to compare Chinese models with global leaders.
By some metrics, Baidu’s ERNIE Bot is a GPT-4–level model (see Figure 5), along with Zhipu AI’s GLM-4, and it is likely that Moonshot AI will release a GPT-4–level model soon. Indeed, among close watchers of Chinese LLM development and benchmarks, there are some who believe that the top fifteen Chinese companies likely caught up with GPT-3.5 performance by the end of 2023, and more may be able to catch up to GPT-4 by mid-2024. However, these are complex issues to unpack, and “catching up” with GPT-3.5 appears to be relatively easy, while catching up to GPT-4 is much more difficult. Once GPT-5 is released, the benchmarking game will enter new territory.
Indeed, with the rapid evolution of leading-edge models such as Gemini, Claude, and Llama-3, and soon-to-be-released models like GPT-5 (possibly within months), benchmarking remains a moving target. This poses ever-evolving challenges for Chinese AI firms in terms of developing metrics to assess their own capabilities. Chinese firms are currently considering how to approach benchmarks across a range of features:
- Multi-modal understanding and generation. With Gemini and similar technologies, LLMs are not just limited to text but can also process and generate other modalities like images, audio, and video. This necessitates new benchmarks that assess a model’s ability to understand and generate content across different modalities, rather than just text alone.
- Increased context windows. Larger context windows allow LLMs to process and remember more information at once. This could lead to the development of more complex benchmarking tasks that require understanding and referring to larger bodies of text or multi-modal content, thereby testing the model’s long-term memory and contextual understanding. Moonshot AI in February updated its Kimi chatbot to handle up to two million Chinese characters via the context window.
- Cross-modal reasoning. Benchmarks might need to assess a model’s ability to perform reasoning across different modalities. For example, understanding a text passage and relating it to an associated image or vice versa.
- Real-time interaction and adaptability. With advancements in multi-modal models and context windows, benchmarks may also evolve to test a model’s ability to interact in real-time scenarios and adapt to new information or changing contexts.
- Cultural and linguistic nuances. For Chinese LLMs, it is important that these benchmarks take into account the unique cultural and linguistic nuances of the Chinese language and its various dialects, especially when interpreting and generating multi-modal content.
- Dataset diversity and inclusivity. The benchmarks will need to include diverse and inclusive datasets that represent a wide range of modalities, dialects, cultural contexts, and use cases relevant to Chinese users. Here the challenge for Chinese LLM developers will be gaining access to broader, non-text, culturally specific datasets to train models.
- Ethical and responsible AI. With the increase in capabilities, benchmarks will also need to consider ethical aspects, like how well the model avoids generating harmful or biased content, especially in a multi-modal context that is more complex and susceptible to misinterpretation.
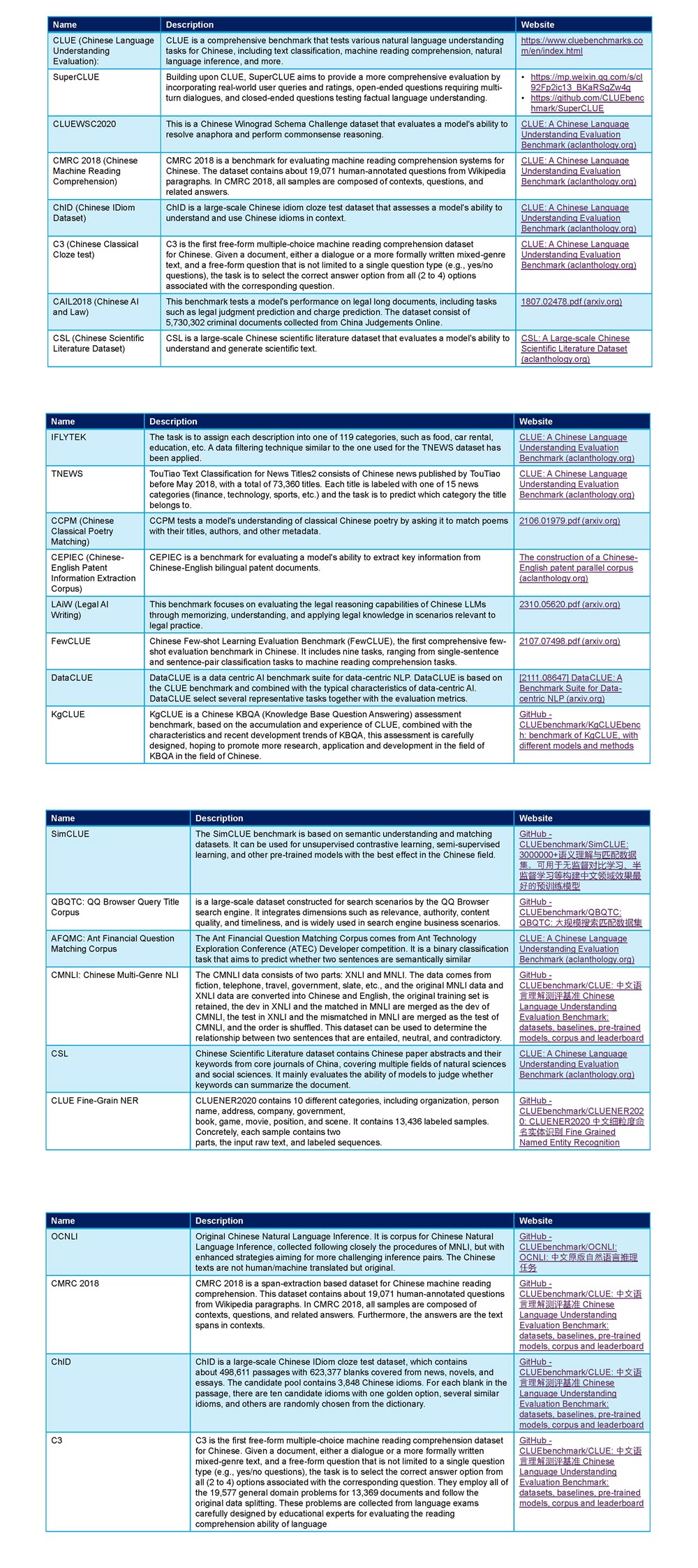
- Integration with existing benchmarks. Existing Chinese-language-specific benchmarks like CLUE and CMRC (see Table 2) might be adapted or extended to include multi-modal aspects and larger context windows, thereby expanding their scope and relevance.
Hardware Issues Facing Chinese LLM Developers
U.S. controls on GPUs ramped up on October 17, 2023, and continue to roil long-term thinking in China’s LLM development ecosystems around how to maintain long-term reliable access to advanced compute. This issue will become increasingly pressing for Chinese AI firms. The U.S. Commerce Department has drafted a proposal that will require U.S. cloud services providers like Google Cloud, Microsoft Azure, and AWS to report who is using their services to train LLMs of a certain size and compute requirement. Such reports will likely be submitted to an office under the Bureau of Industry and Security, which also oversees export controls. The move is designed to close a gap, perceived by proponents of the controls as a loophole, in the October 7, 2022, controls on GPUs that allows a Chinese firm to access forbidden GPUs like the Nvidia A100, H100, or newer G200 or AMD’s advanced GPUs in the cloud via Infrastructure-as-a-Service (IaaS) channels.
However, the overwhelming majority of Chinese firms exploring business opportunities using generative AI are unlikely to be affected. Most Chinese firms are relying primarily on the OpenAI GPT-X API, Google’s Gemini, or open-sourced models like Meta’s Llama-2/3, rather than pursuing training of a massive LLM from scratch—which would not need to be reported under current Commerce proposals. Additionally, bigger domestic platforms such as Alibaba, Tencent, Baidu, and Bytedance have stockpiled sufficient advanced GPUs to cover processing power over the next several years and will use their own cloud services and data centers equipped with these GPUs to train their models. Smaller start-ups that are looking to train new models will turn to these players, not AWS or Google. Other key players like Huawei will increasingly rely on their own cloud services powered by domestically produced Ascend 9XX series chips and look for novel ways to configure their own hardware and GPU capabilities to optimize for large model training.
Over a longer timeframe, however, hardware issues will become an increasing challenge for Chinese firms. Large U.S. AI players such as OpenAI, Google, and Meta are building compute infrastructure using tens or even hundreds of thousands of advanced Nvidia GPUs, such as cutting-edge GH100s, and later this year or next year will install the new bleeding-edge Blackwell systems announced at the Nvidia GTC event in late March. Amassing so many advanced GPUs is largely out of reach for Chinese technology platforms and start-ups. For Chinese LLM firms, the only way to stay competitive will likely be via leveraging open-source tools.
The critical question for Chinese firms, then, is whether companies like Meta, Google, and French leader Mistral will continue to open source increasingly advanced models as they emerge. If not, Chinese companies would be pushed toward more innovative solutions, such as developing smaller but very capable models that are still suitable for certain applications. For example, Llama-2 with 7B parameters performs better than GPT-3—and in some cases at the same level as GPT-4—meaning Chinese companies can similarly train smaller models using fewer GPUs. Indeed, over the next twelve to eighteen months, Chinese LLM developers will have access to enough advanced computing power, based on stockpiled A100, H100, A800, and H800 GPUs, and a mix of domestic GPUs from players such as Biren Technology, Moore Threads, and Huawei, to be able to train most models, particularly smaller models. But the lack of reliable volumes of GPUs over the long term will push Chinese firms to innovate at a different rate from their Western counterparts.
Therefore, the longer-term answer to AI training hardware in China appears to be Huawei. Last year, it introduced the Atlas 900 Supercluster, consisting of thousands of Ascend 910s. Huawei asserts that it can train foundation models with over 1 trillion parameters and is intended to be a direct competitor to similar systems offered by Nvidia. The challenge will be whether domestic foundry leader SMIC, working with Huawei engineers, can scale up to meet demand for its hardware such as the Ascend series and Kirin 9XXX process for Huawei’s smartphones. Capacity at SMIC for more advanced processors made using a 7-nm process is limited but still expanding. U.S. export controls are affecting SMIC’s ability to expand production, but the firm is working more closely with domestic tool makers and leveraging Huawei’s extensive experience with design and manufacturing. How quickly Huawei and SMIC can ramp up production of these advanced semiconductors and move toward incorporating more advanced memory and packaging as Nvidia, AMD, and Intel continue to do for their GPU designs remains unclear.
Additionally, Huawei is now offering so-called AI-in-a-box systems that feature the Ascend series chips. The firm has reportedly been able to sell the box and associated services to at least a dozen AI start-ups to assist them in selling systems—essentially, private cloud installations—for enterprises that include the AI start-ups’ LLMs. Customers include start-up Zhipu AI and iFlytek, and Huawei estimates the market for this type of system could reach $2.3 billion this year, while estimates for government use of AI boxes by 2027 run much higher. Zhipu AI bundles eight Huawei Ascend 910 chips with its 12B parameter model and charges $250,000 per year for the system. Other companies such as CloudWalk are also competing in this private cloud market, touting its advantages for information security and data privacy and noting that these systems can support both training and inference.
Broader technology trends in the generative AI sector could also play to the advantage of Chinese firms. At the recent gathering of world and industry leaders at Davos, one of Meta’s key AI developers Yann LeCun noted that text-based LLMs are reaching a peak in terms of their ability to leverage more training data—there is not much more new data out there to train on. LeCun emphasized that the next step is multi-modal models, and these may not need to be as big as—or use as much compute as—LLMs. Significantly, the model architecture has not yet solidified for optimally handling video and images. While the transformer (the T in GPT) has proven to be very effective for handling written language, it is not as optimal for video and images. For example, Google’s just-released Gemini Ultra is a multi-modal model that is massive, but so far it does not appear to be significantly better than GPT-4. Nonetheless, companies such as Bytedance, Tencent, and Kuaishou have access to significant volumes of video and image content, which could provide some advantages in training multi-modal models. In March, Kuaishou officials claimed that their KwaiYii LLM had surpassed GPT-3.5 in overall performance and was approaching GPT-4 in some areas. The firm claimed its KeTu text-to-image model had exceeded some benchmarks achieved by MidJourney 5, an image generation service released by Midjourney a year ago. Tencent also claimed that its Hunyuan LLM was “among the world’s best”—particularly in terms of the model’s ability to create images and videos based on text prompts. In late May, Tencent launched a new assistant based on Hunyuan, Yuanbao AI. that can summarize documents and generate texts and images.
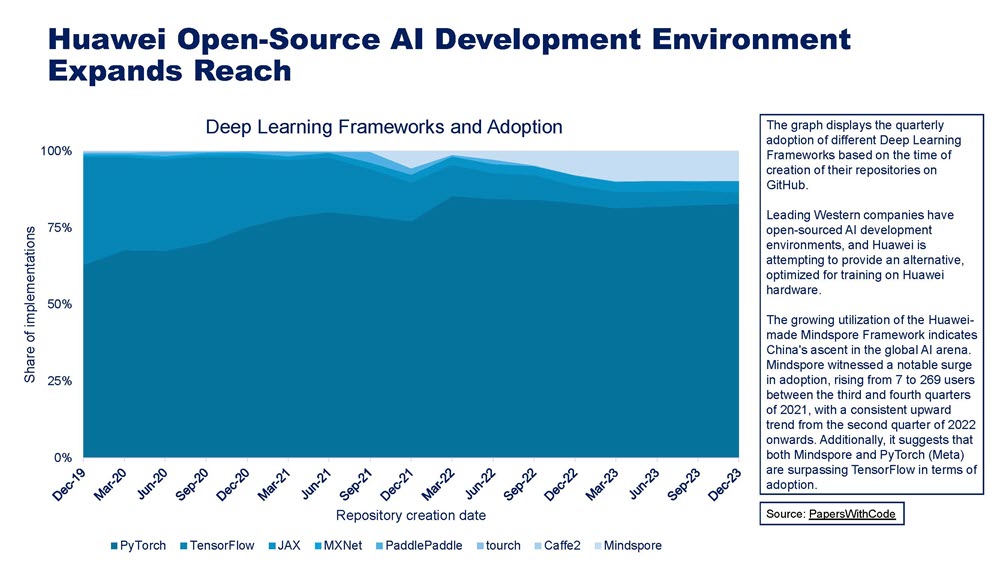
Alternatives to PyTorch and TensorFlow with CUDA in China’s AI Development Stack
The question of whether Chinese firms will be able to access advanced GPUs goes beyond hardware. The development stack is also at play. Currently, the dominant AI development toolkits globally are open-source development environments such as PyTorch and TensorFlow, coupled with Nvidia’s CUDA libraries running on Nvidia GPUs. Huawei and Baidu offer alternative environments—MindSpore and PaddlePaddle, respectively—but Huawei has an advantage over Baidu due to the fact that its AI-focused semiconductors, the Ascend 9XX series, are considered more powerful than other domestic alternatives including those used by Baidu and may be on par at this stage with the Nvidia A100 GPU. Indeed, discussions with Chinese AI industry observers over recent months reveal a widespread belief that Huawei is the only company with a chance to develop as an alternative to Nvidia for China. Some believe this process will take time but that Huawei will eventually develop a hardware-software stack that creates the kind of synergies that Nvidia’s close coupling of GPUs and software development environments provides to programmers. However, the current industry consensus is that Huawei’s products are not remotely competitive with Nvidia or AMD in terms of hardware-software synergy. Indeed, despite the fact that comparisons of raw technical performance parameters between Nvidia A100 chips and Huawei Ascend 910B chips seem to indicate the chips are relatively comparable, the numbers do not necessarily reflect performance in real-world applications.
Switching development stacks is a painful proposition for developers, raising the question of how dependent Chinese AI firms currently are on foreign open-source frameworks. While determining framework usage among developers is challenging, since many companies and researchers do not disclose their internal tools and practices, some signs indicate that foreign open-source tools are widely used. For example, a 2021 survey by the China Academy of Information and Communications Technology, a government-affiliated think tank, found that PyTorch and TensorFlow were the most widely used frameworks, followed by MindSpore and PaddlePaddle. However, there are also some indications that adoption of MindSpore is poised to rapidly increase, including the following:
- Adoption by Huawei and its partners. As MindSpore is developed by Huawei, it is likely to be widely used within Huawei and its partner companies for developing AI models, including LLMs. Huawei has a significant presence in China’s technology industry, which could contribute to MindSpore’s adoption. MindSpore is not showing up on industry surveys of development environment market share (see Figure 6).
- Growing open-source community. MindSpore has an active open-source community, with a growing number of contributors and projects on platforms like GitHub. This suggests that there is significant interest in MindSpore among Chinese developers and researchers.
- Performance on benchmarks. MindSpore has been used to train several state-of-the-art Chinese LLMs, such as PanGu-Alpha and Noah-Alpha, which have achieved top results on various Chinese natural language processing benchmarks. This demonstrates MindSpore’s capability for training large-scale models efficiently.
- Government support. The Chinese government has been actively promoting the development of domestic AI technologies, including frameworks like MindSpore, to reduce reliance on foreign tools. This policy support may encourage more Chinese companies and researchers to adopt MindSpore.
The Evolving Open-Source Debate in China
Though Chinese developers are currently heavily dependent on foreign open-source models, signs indicate that regulators may be moving to encourage—and perhaps eventually force—developers to use domestic alternatives. Despite the fact that a number of major Chinese tech platforms, including Alibaba, are hosting Western open-source models, such as those developed by Meta, Google, and Mistral, TC260 (China’s leading standards body) issued finalized security requirements around generative AI-based applications such as chatbots in early March. These security requirements, while not formal regulations, may be used by regulators when assessing which AI-driven tools are permitted to operate in China. The requirements suggest that AI firms should only develop AI tools based on large models that are domestically licensed, which many foreign open-source models are not. Considering that there are already many companies developing applications built on foreign LLMs, it remains unclear if, when, or how the CAC will implement a clear regulation governing the use of foreign LLMs in China based on these security requirements. This issue is complicated, as foreign companies may be forced to use models for their applications in China that have CAC approval, while Chinese firms using foreign open-source models may be restricted from using them in China.
That said, policymakers in China are aware that pulling this rug out from under local developers would damage domestic AI competitiveness unless equivalent domestic alternatives are available, and as such, they are moving to accelerate the development of those alternatives. At a developer conference in Shanghai in March, city officials indicated that they intend to funnel support for domestically developed open-source models. This issue was also raised by multiple representatives at the 2024 Two Sessions, China’s main annual legislative meeting.
This sense of urgency is heightened by the increasing attention that U.S. regulators are paying to the issue, which has generated concerns that the United States or other foreign powers may eventually move to choke off China’s access to foreign models or development stacks. The U.S. Commerce Department is currently seeking input on the potential risks and benefits of open sourcing advanced models, an issue that will become more salient if open-source models catch up to proprietary models such as GPT-4 in the near future. These concerns over access to near-frontier AI models continue to be a focus of governments.
China’s AI industry is engaged in a debate about the wisdom and risks of open sourcing their own advanced AI models. A small number of Chinese AI companies and organizations, including Alibaba and the Beijing Academy of Artificial Intelligence, have open sourced some models, while others are considering it. But there is not a clear counterpart to a large company like Meta open sourcing an advanced model such as Llama-2. Those pushing open sourcing of more advanced LLMs believe that it will spur innovation and accelerate research by fostering a collaborative environment, lead to broader application of LLMs, provide for community engagement and feedback, and provide educational benefits. Companies that do not favor open sourcing of powerful LLMs are concerned that the models could be leveraged by malicious actors and that loss of control could result in quality and reliability issues. Companies like leader OpenAI believe in keeping models proprietary to protect intellectual property and commercial interests.
Outside China, companies are also taking sides in the debate over the open sourcing of models. OpenAI is part of the Frontier Model Forum—which also includes members such as Anthropic, Google, and Microsoft—and promotes AI safety, but the company does not support open sourcing of AI models. By contrast, in early December, IBM and Meta formed the AI Alliance, designed to promote open sourcing of AI models. So far, no Chinese companies are members of either organization, even though firms such as Bytedance, Alibaba, Tencent, Huawei, and 01.AI are among global leaders in developing and deploying applications based on LLMs.
Chinese Investments in AI Ramp Up
In 2023, Chinese AI start-ups engaged in an arms race for capital, with a total of 26 generative AI start-ups landing significant investments. New AI companies such as Baichuan AI, MiniMax, and Zhipu AI saw valuations ranging from $1.5 billion to $2.0 billion. Other notable beneficiaries of large-scale investments include Moonshot AI and 01.AI. Significantly—and similar to previous bouts of investments in emerging technologies—China’s major cloud and e-commerce platforms, including Alibaba, Tencent, Meituan, and Ant Group, are investors in some of these start-ups, along with smart device companies such as Xiaomi. Among these, it is most notable that, as is the case in the United States, Chinese LLM start-ups are obtaining investments from large hyperscalers, investments that include access to compute. Alibaba, in particular, has adopted a more aggressive investment strategy in AI start-ups and is positioning the company to be a key player via Alibaba Cloud. In late May, for example, Alibaba announced an $800 million investment in Moonshot AI. Tencent could also invest in Moonshot AI in a new funding round that could value the company at $3 billion. Alibaba now backs all the so-called AI tigers. In addition to Moonshot AI, it holds stakes in MiniMax, Zhipu AI, and Baichuan (see Figure 1). A Tencent investment in Moonshot AI would put it in a similar place as Alibaba.
In addition, in late May, Zhipu AI announced that Saudi VC firm Prosperity7—the VC arm of oil giant Aramco—had made a $400 million investment in the firm. This is the first time a foreign investor has taken a major stake in a firm in China’s generative AI sector. This could prove significant if other well-funded Middle Eastern government–affiliated investors or sovereign wealth funds decide to invest in Chinese AI start-ups. Despite growing U.S. sensitivity to large investment funds in Saudi Arabia and the United Arab Emirates investing in Chinese firms or hiring Chinese software engineers and using Chinese IT equipment, countries in the Middle East appear to want to avoid dependence on U.S. AI firms.
Chinese VCs such as Sequoia China (recently rebranded as HongShan), Hillhouse Capital, Joy Capital, and Shenzhen Venture Capital have also joined the fray. However, Chinese VC companies are approaching the generative AI era with some caution, as many were burned by the lack of successful major AI players during previous waves of AI development. For example, companies like Megvii, SenseTime, Yitu, and CloudWalk, known as the “four little dragons of AI,” came with large valuations and high hopes. But after facing challenges such as weak profitability and placement on the U.S. Commerce Department Entity List for allegedly supporting public security organs using facial recognition applications, including targeting the Uighur minority population, they have not been able to raise capital easily.
As a result, only SenseTime and CloudWalk were eventually able to go public, but their stocks until recently have not done well, and their profitability remains weak. In April, SenseTime stock rebounded significantly after the release of its next-generation SenseNova 5.0 LLM and the announcement of cooperation with Huawei on domain-specific models. SenseTime claimed that SenseNova 5.0 is “comparable to GPT-4 Turbo”—the multi-modal model is trained on 10 terabytes of data that includes synthetic data. In terms of benchmarks, the SenseChat 5.0 LLM based on SenseNova topped both Llama-3 70B and GPT-4 Turbo for Massive Multitask Language Understanding and HumanEval, according to OpenCompass. Smaller models from SenseTime also beat some well-known Western models such as Llama-2 for Chinese-language specific benchmarks. Reflecting SenseTime’s long experience with images, SenseNova-based vision language models performed close to GPT-4V and Gemini Pro for key benchmarks such as Massive Multi-discipline Multimodal Understanding, ChartQA, and MathVista. The collaboration with Huawei includes models optimized for the firm’s Atlas platform, which uses Ascend 910 processors for running models for software coding, healthcare, government services, and finance. The company also claims to have 45,000 GPUs.
SenseTime’s rebirth as a major player in China’s generative AI space is significant, given that it is a public company, has lots of experience with AI applications in different industries, and apparently has access to a significant amount of compute. It also has a collaborative deal with Huawei, including on facial recognition platforms that leverage Huawei hardware. This may be a hint of the future direction of LLM development, with companies like SenseTime working more closely with Huawei for access to compute on platforms such as the Atlas 900.
Chinese VC firms are now eager to see generative AI companies move to profitably quickly—at least faster than the previous wave of AI firms that foundered in a tough market under U.S. technology restrictions. U.S. investors and companies backed by major technology platforms are likely to be more patient with generative AI investments. Companies that are already major players, such as Microsoft-backed OpenAI and Canada’s Cohere, are generating significant revenue, something no Chinese generative AI company appears to be doing yet.
In an interesting development in late May and early June 2024, many of the leading LLM developers reduced prices for AI services. ByteDance, Alibaba, and Tencent drastically reduced prices on their LLM services to outcompete OpenAI’s ChatGPT. A premium offering from ByteDance’s Doubao Pro now costs 0.011 cents per 1,000-token prompt, 99.8% less than what it costs to access GPT-4. In addition to Bytedance, Alibaba, and Tencent, other major Chinese tech companies such as Baidu and iFlytek have also cut prices on their LLM application program interfaces (APIs). Companies developing LLMs are now typically deriving revenue by charging for API access for developers and enterprises, allowing them to integrate LLMs’ language-processing capabilities with applications using company data. LLM APIs allow developers to send text queries to a LLM running in the cloud and receive processed outputs. The pricing for these APIs is most typically calculated on a per-million-token basis. For example, OpenAI charges $0.5–$1.5 per million tokens for input/output for its ChatGPT-3.5 model. So far, the reduced prices primarily apply to model inference for some lightweight language models and do not apply to fine-tuning and large-scale deployment of bigger models. Thus, the primary goal of the price reductions appears to be to attract developers to use a particular company’s model, as they would lower the barrier for developers to experiment with AI applications. In addition, it would help accelerate AI adoption and innovation among developers and enterprises. It is unlikely, at least initially, to significantly affect enterprise clients. The new price war reflects the fact that China’s generative AI market is extremely competitive. The intense competition is likely at some point to force some smaller AI firms out of the market, leading to industry consolidation.
Hence for Chinese AI start-ups developing frontier models, there will be pressure to prove to investors that they can generate revenue in the short-term—meaning this year rather than in three to five years.
The Path Forward for China’s AI Ecosystem
Chinese companies in the coming months will be working to solve tough issues such as securing long-term access to reliable sources of compute, cultivating a viable domestic alternative model development environment, determining how and when to leverage Western open-source models, and continuing to develop applications that generate revenue, focused primarily on the enterprise market, and competing for talent.
Chinese firms face hurdles in catching up with their Western competitors, and industry leaders in China clearly recognize these challenges. In early April 2024, Alibaba co-founder Joe Tsai asserted that Chinese AI companies were two years behind their U.S. rivals. One primary factor cited by Tsai was access to advanced hardware for training. Claims designed to alleviate the growing anxiety within the Chinese AI sector about the future and the capabilities of Chinese LLMs, such as Baidu CEO Robin Li’s assertion in March that ERNIE Bot is better than GPT-4 for generating Chinese poetry in the style of the Tang Dynasty era, generate headlines but do not represent a significant breakthrough in model development. In early May, Chinese media entrepreneur Zhao Hejuan stressed that when ChatGPT-5 is released, this perceived gap of one to two years could mean that China falls as much as ten years behind the United States. Zhao highlighted a number of factors contributing to the gap, including China trailing in top-tier, advanced, and most impactful research; the inability of Chinese firms to retain top talent; and shortfalls in the quality of Chinese datasets.
AI start-ups in 2024 will continue to struggle with access to compute, particularly given the changing cost of cloud services due to tightening U.S. controls on advanced GPU exports to China. Indeed, rapidly fluctuating computing power rates in China have made it difficult for AI firms to plot a steady course for development. By one estimate, the contract price that LLM start-ups are paying to cloud services providers has increased by 50% since last summer. Moonshot founder Yang Zhilin noted that for a significant period of time the price of access to GPUs was changing every day: “The price keeps changing, and the strategy must also keep changing. There are many differences between what channel to choose, buy or rent.” This gives companies like Alibaba the leverage to invest in start-ups via compute credits. It is likely that the large hyperscalers like Alibaba, Baidu, Tencent, and others are reserving compute access for their own LLM development and for companies that they are heavily invested in, such as MiniMax and Moonshot for Alibaba.
The cooperation now being seen between the VC arms of large technology players, particularly Alibaba and Tencent, and the large numbers of VC firms invested in the six or seven leading start-ups will need to see some of these firms have breakthroughs in model development in the next six to twelve months, either by integrating foreign open-source technologies or through modifying and copying them, to create models and applications that will do well in the Chinese market. Companies investing in these start-ups are also attempting to spread the risk by pooling resources, given the high capital costs of obtaining computing power to train models. According to a founding partner at Crystal Stream Capital, “this means that these LLM companies will not just have a few shareholders but many—everyone is swarming in, and everyone is diversifying their risks.” This reflects the practical tendencies of China’s VC today, according to industry observers.
However, there remains a major debate within China’s AI community about what start-up companies focused on LLMs should prioritize. Should they give preference to commercializing LLMs and developing practical applications, or should they seek to develop their own proprietary capabilities without reference to Western models and focus on long-term development of artificial general intelligence (AGI)? Moonshot founder Yang Zhilin appears to be a firm believer in the need to pursue AGI, but others, such as Allen Zhu, a well-known venture investor, are skeptical, given the open sourcing of models and the heavy investments in hardware required to develop models from scratch. This debate will continue, with factors such as access to reliable long-term sources of advanced hardware complicating the picture.
In early March, there were signs that local governments were also prepared to assist AI start-ups with the problem of high costs for access to computers in the cloud. Some seventeen municipal governments, including Shanghai, pledged to provide “computing vouchers” to AI start-ups facing rising costs for data center access to compute. These credits provide amounts up to around $300,000 to be used to pay for compute time for training LLMs.
Chinese companies developing LLM models, as well as Chinese government officials eager to promote the competitive position of Chinese firms in the generative AI space, will continue to look to the United States and LLM leaders such as OpenAI, Google, Anthropic, and Meta for reference points in assessing domestic progress and innovation in the sector. With an initial and comprehensive set of regulations now in place around generative AI (see, for example, Matt Sheehan’s summary of this here), Chinese regulators appear more focused on enabling companies in the sector to succeed and compete with Western peers. This is happening on multiple fronts, from developing national compute capabilities, as we detailed here, to releasing datasets that could be used to train new multi-modal models. The importance of the national compute issue was highlighted again in late March, when the director of the National Data Administration, Liu Liehong, weighed in on the importance of the National Unified Computer Power Network (NUCPN) for AI in an unusual commentary in the party’s top theoretical journal Qiushi. Liu stressed the importance of the NUCPN for China’s ability to maintain competitiveness in AI by boosting the country’s overall capacity to support compute-heavy application development.
With some of the latest advancements involving multi-modal models and context windows capable of ingesting different types of data, the next six months will see a lot of announcements in China in areas like text to video. In late February, for example, People’s Data announced it had compiled a semantic corpus of news-related data amounting to 300 million items, specifically to support the development of Sora-like applications. Sora, which can generate high-quality videos from text prompts, was released in February 2024 by OpenAI, and has created major ripples in the Chinese AI sector, with some suggesting that it shows how far behind Chinese generative AI companies are in comparison with leaders such as OpenAI. Chinese companies are already responding to the challenge posed by Sora. In early March, a team of researchers from Beijing University and Rabbitpre, a Shenzhen-based AI company, jointly launched the Open-Sora project, with the goal of reproducing Sora. Additionally, social media giant Bytedance late last year released its MagicVideo text-to-video model. Tencent and Alibaba’s Damo Vision Intelligence Lab have also released text-to-video tools. In April, Shengshu Technology, a Tsinghua University spinoff company backed by Ant Group, Baidu Ventures, and Qiming Ventures, among others, released Vidu, a text-to-video platform that the firm claims is nearly on par with Sora. Early evidence suggests it is not quite as good but is likely still the second best such model out there. The firm had open sourced its text-to-image model UniDiffuser in 2023.
In addition, in April, Meta released Llama-3, and within three days there were six fine-tuned Llama-3 based models on Hugging Face. The release of Llama-3 and soon GPT-5 will be a critical moment for Chinese open-source LLM developers. As Tony Peng noted on his Recode blog, “the rationale for developing a model becomes questionable” if these fine-tuned Llama-3 based models match or exceed the benchmarks of leading Chinese open LLMs. But for the sector as a whole, the open-source and Llama-3 issue will not likely affect well-financed start-ups such as Moonshot, MiniMax, and Zhipu AI. All the leading cloud makers moved to host Llama-3 model versions in April—Baidu and Alibaba Cloud are supporting the Llama-3 8B model, with Baidu also supporting the 70B version and Tencent assisting developers to fine-tune Llama-3. A major issue is that large enterprise users of small or large LLMs will continue to prefer using domestically developed LLMs and could shy away from domestic versions based on Western open-source models such as Meta’s Llama-2/3 or Mistral models to avoid regulatory risks. In another trend likely to expand, Alibaba claimed in early June that its latest open-source model Qwen2 had beaten Llama-3 in benchmarks related to math and computer coding. This announcement came just one month after Alibaba had released Qianwen 2.5, a closed-source model that the firm claimed performed better than GPT-4 in some benchmarks. Benchmarking against both proprietary and open-source models will be the norm going forward.
The software development environment issue will be a challenging one going forward, but clearly there are those in China who understand the issue and are looking for solutions. One of the policy proposals before the Two Sessions meetings in Beijing in March 2024 was from Cao Peng, chairman of JD.com’s Technology Committee, who stressed the need for domestic AI hardware to be compatible with and closely developed with domestic software. In addition, Baidu CEO Robin Li asked policymakers to boost efforts to support innovative software and AI.
Finally, the 2024 Government Work Report released during the March meeting of the National People’s Congress hinted at the imminent launch of a new policy initiative designed to boost Chinese company competitiveness in AI, called the “AI Plus” (AI+) initiative, which could be similar to the “Internet Plus” initiative launched in 2015. Internet Plus included separate plans to boost the digital footprint of industries, including healthcare, education, and manufacturing. The AI Plus initiative will likely be designed to do something similar, with the government providing some support for upgrades to traditional industries through leveraging access to AI platforms. Given the experience of Internet Plus, which benefited big tech platforms, it is likely that the AI Plus initiative could benefit semiconductor firms and data centers, as well as AI developers that can align their priorities with the new initiative.
In addition, AI Plus is also being linked now with the NUCPN, and AI is clearly a key element of the “new productive forces” concept first mentioned by Xi Jinping in September. In early April, China’s State-owned Assets Supervision and Administration Commission of the State Council identified the first batch of state-owned start-up companies in emerging fields like AI, quantum information, and biomedicine designated as part of developing “new productive forces.” How government support for AI via these initiatives will translate into progress within the private sector that is driving AI development broadly and generative AI in particular remains unclear, but the government initiatives send a strong signal that Beijing will continue to support emerging technologies and believes that AI will be a key driver of future economic growth. Hence, the year 2024 will be a critical one for the AI sector in China, on many fronts.
Implications for U.S. AI Policy and Global AI Governance
Even as Beijing prioritizes support for AI and China’s semiconductor industry, U.S. policymakers will face challenges in attempting to slow China’s development of frontier AI models. In the coming weeks, the Biden administration will launch a working group on AI that will tackle issues related to the development and deployment of advanced AI models. Both countries agreed to establish a dialogue on AI at the November 2023 bilateral meeting in San Francisco, and in mid-May the United States and China kicked off a new U.S.-China AI Dialogue in Geneva. The meeting was co-chaired by Yang Tao, director-general of the Department of North American and Oceanian Affairs at the Chinese Ministry of Foreign Affairs, and Seth Center, the State Department’s acting special envoy for critical and emerging technology, along with Tarun Chhabra, the White House National Security Council’s senior director for technology and national security. Representatives from China’s Ministry of Science and Technology, the National Development and Reform Commission, the CAC, the Ministry of Industry and Information Technology, and the Foreign Affairs Office of the Chinese Communist Party Central Committee participated in the dialogue.
According to the Chinese readout of the meeting, both sides exchanged views “in-depth, professionally, and constructively” on the risks of AI technology, global governance, and other issues of mutual concern. The makeup of the U.S. delegation suggested that the United States placed most emphasis on the national security aspects of the deployment of AI, with the U.S. readout of the meeting noting that the United States expressed concern about the misuse of AI, including by China. The Chinese delegation stressed that China supports stronger global governance of AI and is willing to strengthen communication and coordination with the international community, including the United States, to form a widely accepted global framework and standards for AI governance. The Chinese delegation was also highly critical of U.S. “restrictions and pressure” around AI, a reference to export controls and other measures targeting the sector in China. It remains unclear how the dialogue could integrate private-sector AI companies. Many leading Chinese AI firms are on U.S. technology control lists, and previous attempts by the Chinese side to include such companies have resulted in cancellation of private-sector participation in dialogues, such as on commercial issues.
U.S. policymakers engaging with Chinese officials on AI governance and other issues related to AI will face a number of challenges. While there is a growing consensus in the United States and among allies that the Chinese government and Chinese AI companies should not be left out of the growing global discussion about developing a regulatory framework around frontier AI models, fully including China in key initiatives such as the Bletchley Park efforts remains very much a work in progress. Comments like those by Secretary Raimondo on the goal of U.S. GPU controls to prevent China from training frontier models will make it difficult to develop areas where both sides can see the benefits of cooperation. While there can be general agreement on high-level principles around AI development, going beyond this and allowing companies to have models tested by organizations affiliated with other governments will remain problematic. For example, while the United States and the United Kingdom recently signed an agreement for collaboration between their AI safety institutes, it is unlikely that Beijing would allow its companies to participate in any testing of advanced models that was overseen by the United States or the UK.
In a major development in late May, Zhipu AI was allowed to sign on to an agreement committing firms to publish safety frameworks at the Seoul AI Safety Summit, a follow-on to last November’s UK AI Safety Summit in Bletchley Park. Major Western firms, including OpenAI, Google, and Anthropic, also signed on. The Chinese company’s participation, which was almost certainly fully vetted with the emerging Chinese AI interagency, was likely a trial balloon for Beijing to determine the implications of Chinese companies making this type of commitment. Significantly, though, China did not sign the ministerial statement that was also issued in Seoul. Meanwhile, other governments—led by the United States and the UK—stressed the importance of interoperability between governance frameworks, plans for developing a network of safety institutes, and engagement with international bodies to develop a similar agreement to the Bletchley Park Declaration—which China did sign—to collectively address AI risks. While it is not fully clear why the Chinese government delegation chose to not sign the new agreement, the reason was likely related to language about the use of AI to foster “shared values” and the lack of language on the United Nations’ role in the process, something Beijing has frequently advocated. The next iteration of the Bletchley Park Initiative will be held in Paris in February 2025. The issue of China’s participation, at both the government and particularly the company level, in various elements of the process will continue to be contentious.
In addition, in June a series of new developments highlighted the challenges both governments will face as companies push into each other’s markets using generative AI applications. First, Moonshot AI has released products that are being used in the United States, including Ohai, an AI role-play chat app that is currently available from both the Google and Apple app stores. The firm is also using its generative AI algorithms on a new site called Noisee, which includes a music video generator. Furthermore, it is preparing an international version of its popular chatbot Kimi for users outside China, including in the United States. Second, MiniMax is targeting the U.S. market via another AI chat app called Talkie, which already has 11.4 million monthly active users in the United States using its iOS and Android versions.
There is currently no clear legal restriction on the deployment in the United States of AI applications developed in China. The apps, however, could come under scrutiny via the Information and Communications Technology Supply Chain (ICTS) rule. A regulatory framework is currently being developed by the Commerce Department and includes “connected apps” that are controlled by or subject to the jurisdiction of “foreign adversaries,” meaning primarily China. So far the rule has only been used to launch a rulemaking process for connected vehicles, but officials at the Commerce Department are likely to have Chinese AI companies and applications in their crosshairs sooner rather than later.
In addition, following the launch of Apple Intelligence services, the U.S. smartphone and technology giant is looking to partner with a Chinese AI firm to deliver the services in China and is in talks with Baidu, Alibaba, and Baichuan AI. Earlier efforts to convince Chinese regulators to approve a non-Chinese LLM were abandoned because the CAC was unlikely to approve its use. In a similar situation, Samsung has turned to Baidu for its AI phones released in China. These types of regulatory challenges will not become the norm across the AI space, and regulators will be scrambling to come up with a workable framework that clarifies how LLMs developed within the two countries can or cannot be deployed in both markets.
Hence, U.S. policymakers will need to develop new approaches to China and AI—including through the Bletchley Park process (now called the AI Action Summit)—if there is to be any chance for a widely accepted AI governance framework that includes Beijing and Chinese firms. Further export controls on Chinese semiconductor manufacturing companies will make the process even harder. Beijing does not accept U.S. assertions that export controls are focused on narrow technology domains related to national security and military modernization. All the development of frontier AI models in China, for example, is within private-sector AI companies that are pursuing commercial markets for their LLMs. Viable end-use cases for AI algorithms and frontier models are all commercial, including healthcare, enterprise productivity, quality control for advanced manufacturing, and many others. This major disconnect between actual frontier AI development in China and U.S. efforts to slow the ability of Chinese commercial firms to use cutting-edge hardware will continue to make it very difficult to move beyond generalities and agreement on high-level principles in the near term. U.S. policymakers must come up with a much more integrated approach to AI policy and need China to move the issue forward to engage the country with the second-largest number of AI companies and AI development capacity. Without the full participation of China in the global dialogue around AI governance, no internationally applicable agreement will be possible.
Paul Triolo is Senior Vice President for China and Technology Policy Lead at Albright Stonebridge.
Kendra Schaefer is a Partner at the Beijing-based strategic advisory consultancy Trivium China and a Nonresident Fellow at the National Bureau of Asian Research.
Note: The authors would like to thank Munir Jaber, the AI and tech policy consultant at Albright Stonebridge, for his contributions.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}